
Page 35 - EE Times Europe Magazine – June 2024
P. 35
EE|Times EUROPE 35
What Is Nvidia Doing in Automotive?
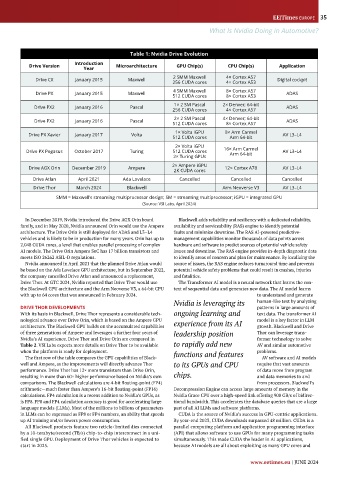
Table 1: Nvidia Drive Evolution
Introduction
Drive Version Microarchitecture GPU Chip(s) CPU Chip(s) Application
Year
2 SMM Maxwell
Drive CX January 2015 Maxwell 256 CUDA cores 4× Cortex A57 Digital cockpit
4× Cortex A53
4 SMM Maxwell
Drive PX January 2015 Maxwell 512 CUDA cores 8× Cortex A57 ADAS
8× Cortex A53
1× 2 SM Pascal
Drive PX2 January 2016 Pascal 256 CUDA cores 2× Denver; 64-bit ADAS
4× Cortex A57
2× 2 SM Pascal 4× Denver; 64-bit
Drive PX2 January 2016 Pascal 512 CUDA cores 8× Cortex A57 ADAS
1× Volta iGPU 8× Arm Carmel
Drive PX Xavier January 2017 Volta AV L3–L4
512 CUDA cores Arm 64-bit
2× Volta iGPU 16× Arm Carmel
Drive PX Pegasus October 2017 Turing 512 CUDA cores Arm 64-bit AV L3–L4
2× Turing GPUs
2× Ampere iGPU
Drive AGX Orin December 2019 Ampere 12× Cortex A78 AV L3–L4
2K CUDA cores
Drive Atlan April 2021 Ada Lovelace Cancelled Cancelled Cancelled
Drive Thor March 2024 Blackwell Arm Neoverse V3 AV L3–L4
SMM = Maxwell’s streaming multiprocessor design; SM = streaming multiprocessor; iGPU = integrated GPU
(Source: VSI Labs, April 2024)
In December 2019, Nvidia introduced the Drive AGX Orin board Blackwell adds reliability and resiliency with a dedicated reliability,
family, and in May 2020, Nvidia announced Orin would use the Ampere availability and serviceability (RAS) engine to identify potential
architecture. The Drive Orin is still deployed for ADAS and L3–L4 faults and minimize downtime. The RAS AI-powered predictive-
vehicles and is likely to be in production for many years. Orin has up to management capabilities monitor thousands of data points across
2,048 CUDA cores, a level that enables parallel processing of complex hardware and software to predict sources of potential vehicle safety
AI models. The Drive Orin Ampere SoC has 17 billion transistors and issues and downtime. The RAS engine provides in-depth diagnostic data
meets ISO 26262 ASIL-D regulations. to identify areas of concern and plan for maintenance. By localizing the
Nvidia announced in April 2021 that the planned Drive Atlan would source of issues, the RAS engine reduces turnaround time and prevents
be based on the Ada Lovelace GPU architecture, but in September 2022, potential vehicle safety problems that could result in crashes, injuries
the company cancelled Drive Atlan and announced a replacement, and fatalities.
Drive Thor. At GTC 2024, Nvidia reported that Drive Thor would use The Transformer AI model is a neural network that learns the con-
the Blackwell GPU architecture and the Arm Neoverse V3, a 64-bit CPU text of sequential data and generates new data. The AI model learns
with up to 64 cores that was announced in February 2024. to understand and generate
Nvidia is leveraging its human-like text by analyzing
DRIVE THOR DEVELOPMENTS patterns in large amounts of
With its basis in Blackwell, Drive Thor represents a considerable tech- ongoing learning and text data. The transformer AI
nological advance over Drive Orin, which is based on the Ampere GPU experience from its AI model is a key factor in LLM
architecture. The Blackwell GPU builds on the accumulated capabilities growth. Blackwell and Drive
of three generations of Ampere and leverages a further four years of leadership position Thor can leverage trans-
Nvidia’s AI experience. Drive Thor and Drive Orin are compared in former technology to solve
Table 2. VSI Labs expects more details on Drive Thor to be available to rapidly add new AV and similar automotive
when the platform is ready for deployment. functions and features problems.
The first row of the table compares the GPU capabilities of Black- AV software and AI models
well and Ampere, as the improvements will directly advance Thor to its GPUs and CPU require that vast amounts
performance. Drive Thor has 12× more transistors than Drive Orin, of data move from program
resulting in more than 60× higher performance based on Nvidia’s own chips. and data memories to and
comparisons. The Blackwell calculations are 4-bit floating-point (FP4) from processors. Blackwell’s
arithmetic—much faster than Ampere’s 16-bit floating-point (FP16) Decompression Engine can access large amounts of memory in the
calculations. FP4 calculation is a recent addition to Nvidia’s GPUs, as Nvidia Grace CPU over a high-speed link offering 900 GB/s of bidirec-
is FP8. FP8 and FP4 calculation accuracy is good for accelerating large tional bandwidth. This accelerates the database queries that are a large
language models (LLMs). Most of the millions to billions of parameters part of all AI LLMs and software platforms.
in LLMs can be expressed as FP8 or FP4 numbers, an ability that speeds CUDA is the source of Nvidia’s success in GPU-centric applications.
up AI training and/or lowers power consumption. By year-end 2023, CUDA downloads surpassed 48 million. CUDA is a
All Blackwell products feature two reticle-limited dies connected parallel computing platform and application programming interface
by a 10-terabyte/second (TB/s) chip-to-chip interconnect in a uni- (API) that allows software to use GPUs for many programming tasks
fied single GPU. Deployment of Drive Thor vehicles is expected to simultaneously. This made CUDA the leader in AI applications,
start in 2025. because AI models are all about exploiting as many GPU cores and
www.eetimes.eu | JUNE 2024